My Usage of DuckDB

DuckDB is certainly one of the most talked about tools in recent data engineering times, and for good reason. Its simplicity, speed, and versatility make it a compelling choice for many scenarios.
Day Job Usage
In my day to day, my usage of DuckDB varies. Our company predominantly uses Snowflake as our primary data warehouse, covering many of the quality-of-life features that DuckDB offers. 90% of our ETL processes are either API calls where we store the JSON in raw form in Snowflake, Excel files or flat files.
Pipeline Troubleshooting
DuckDB has been particularly invaluable for troubleshooting data pipelines. Recently, I was investigating an issue with one of our more complex pipelines, where sales data for a specific date was missing from our final table. After some investigation in Snowflake, the problem narrowed down to two possible causes:
- The data file had not been loaded into Snowflake for some reason.
- The source flat file itself was incomplete or incorrect.
Quickly loaded up DuckDB and ran a simple SELECT filename, * FROM ... and was able to get a good holistic view of what was out there in Azure Blob. A few targeted filters allowed me to drill down to the specific product I was troubleshooting, and poof, there was that missing record right there in Blob. Went back to Snowflake and just needed to COPY (the file) INTO (the table)..., rerun models and all was happy again.
This ease of use is exactly why DuckDB is my go-to for exploring source data. Functions like read_json_auto() and read_parquet_auto() make querying files in Azure Blob effortless and intuitive. I’m sure I could achieve similar results with Snowflake external stages, but DuckDB just clicks with my workflow and involves less fuss to get started
For the most part, this is the only reason I use DuckDB in my day-job is troubleshooting data pipelines and investigating source data stored in Azure Blob. This is one specific example but there are countless others of a similar thing. Outside of work, I am still doing discovery with how to best utilize DuckDB.
Personal Projects
Over the past year, i've started a few weekend projects utilizing DuckDB. Some were worked on longer than a weekend, others were forgotten about as soon as Monday hit. All of them though gave me different perspectives and expectations about DuckDB (and my underlying compute!)
iRacing Stat
My most successful project utilizing DuckDB is iRacingStat, which was an analytical data website to display detailed breakdowns of Users (drivers), series and lap time analysis. Behind the scenes of the platform itself are data pipelines extracting over 3M+ rows a day from iRacing's data API service, and stored in a data warehouse.
In the beginning, iRacingStat started using Clickhouse as the primary data warehouse system. Clickhouse operated fine in the beginning but as time went on and the volume of the data largely increased, performance issues kept stalling the cluster requiring more scaling up and scaling out, which largely increased costs and only slightly resolved the issue. Data quality issues also plagued the warehouse and resolving said issues involved extremely compute intensive queries which would bring the warehouse to a standstill. And with the API service querying the warehouse directly, it also brought the application down with it due to Clickhouse's tight coupling of compute and storage. After investing $300/month in infrastructure costs to keep Clickhouse alone running, I knew it was time to find something more cost efficient.
Then DuckDB released "DuckLake", an apache iceberg-like data storage format, that works near-seamlessly with DuckDB. This gave me ideas on better optimizing the API service and turned some gears on optimizing ETL processes. Over the course of the next month, I spent countless hours migrating my warehouse operations from Clickhouse over to DuckLake. With the migration, I also redesigned ETL processes to better optimize data loading and pre computed data to really speed up the API response times.
After a few months using DuckLake, quite a few issues that I was facing with Clickhouse were mostly resolved. Because of DuckDB feature set of decoupling the compute from the underlying storage, large queries no longer affected application servers anymore and the API so much more snappy. With the increase in query performance and more stability within ETL processes, I felt really confident with the product I was building at the time.
After 9 months of fetching historical data from iRacing's API service, and over 6TB of compressed data stored in GCS, I am still beyond impressed with how well DuckDB & DuckLake hold up. Certain optimizations were taken like splitting date ranges of data into separate tables like LAP_DATA_2025_02 , LAP_DATA_2024_12 etc, which causes some constraints when trying to calculate certain YoY metrics like finding average lap pace across years, but these are easily work around-able constraints by leaning on DuckDB's engine a bit more. To do that type of YoY analysis, I'll query the 2024 table, then 2025 table and use DuckDB's read_csv_auto() function to do that YoY analysis. 1 small step for a massive increase in performance compared to storing BILLIONS of rows in one singular table.
Before making iRacingStat a private project, hosting costs & GCS costs were a little north of $500/month, which was way too much to be spending on a personal project that is not bringing in any reoccurring revenue. Around June 2025, I decided to make iRacingStat a private API service for other developers to tap into for their own data analysis or for their own applications. Pricing is usage based against API calls made against my API service. With 10 active API consumers, I am not breaking even on hosting costs but it does make the trouble worthwhile and continues to motivate me to provide new data solutions to my few consumers.
The relationships I've built with my API consumers have truly made this journey rewarding. I've had the opportunity to sit down with many of them, diving deep into understanding exactly how they're utilizing my API and learning firsthand what analytics they're striving to deliver. These conversations haven't just been insightful—they've directly shaped the evolution of my API service. By closely collaborating with these developers, I've been able to design new features tailored specifically to their use cases, making the API more intuitive and versatile. Watching these talented developers leverage my service to build impressive personal and commercial applications continues to motivate me, reaffirming my passion for data engineering and the powerful impact of thoughtful, user-driven innovation.
iRacingStat Reports
My latest project using DuckDB has been something I am calling "iRacingStat Reports". This project is still in the proof-of-concept phase but is something that has been a ton of fun to work on so far.
The concept here is to build great looking PDF reports based on the iRacing data that i've collected... Though the current POC is actively scraping data against iRacing's API to obtain the data (iRacingStat API integration hopefully will come soon)
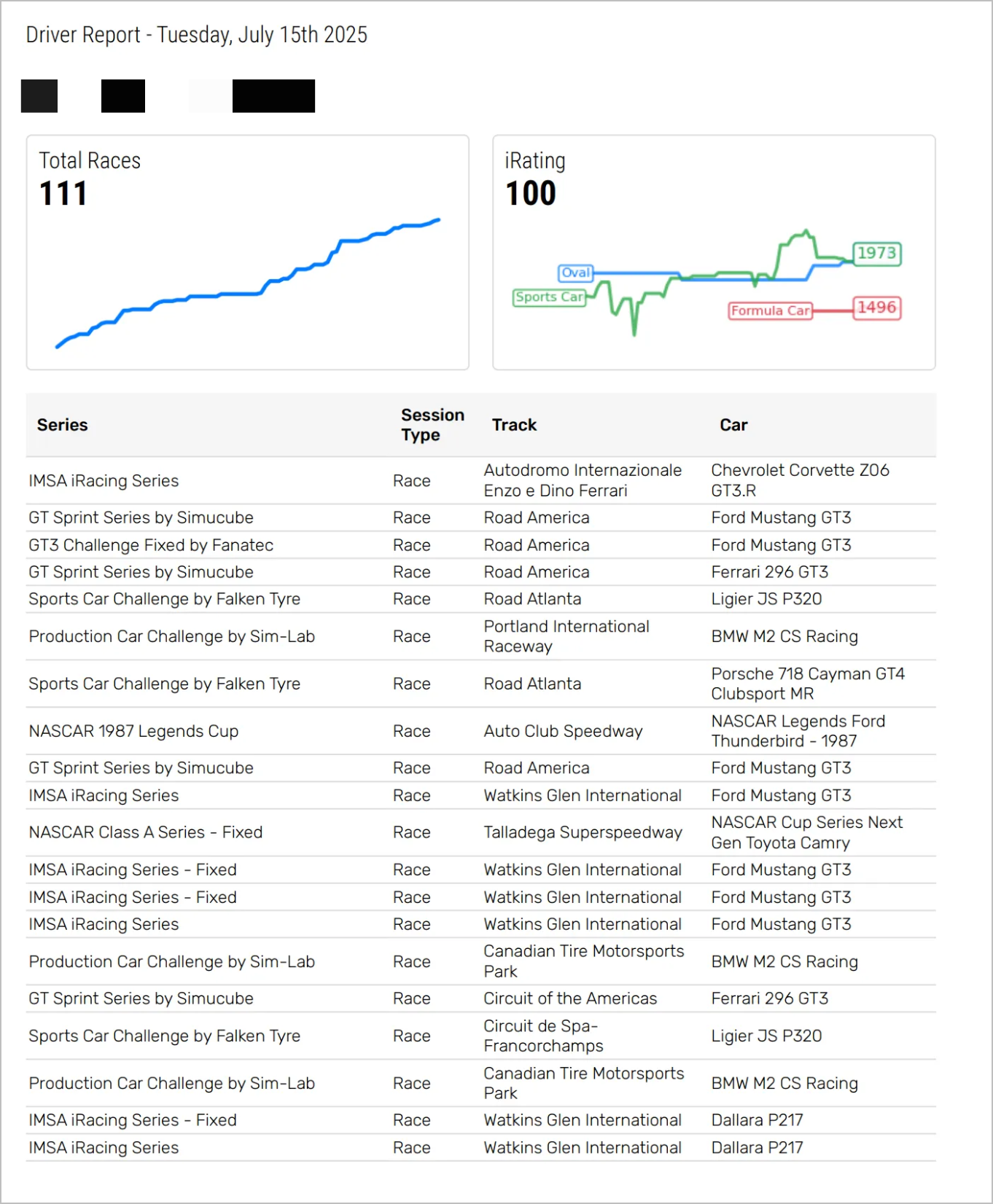
Without going too much in detail of some ongoing work happening at the day job, a few months back, I was tasked with building a PDF to display logistics data sourced from our data warehouse. I had a blast building out that project - it really challenged me in a few ways and developed some new skills along the way. iRacingStat Reports stems from that original work project, but now I get full control over it :)
At a high level- I'm iterating over iRacing's API and storing that information into temporary CSVs to query using DuckDB. I am still figuring out the complete direction I want to take this project but i'm very excited to keep plugging away at this.
Conclusion
Over the past year, i've been trying to plug DuckDB into different workflows and projects to figure out where it works best for what I need out of a query engine. DuckDB's easy to use features and with a similar query syntax and query function featureset that I have available to me in Snowflake has made DuckDB a really easy to use query engine and really easy to pick up for quick troubleshooting tasks in my day to day job operations. I'm excited to keep exploring what this software can do and I hope to make more posts like this one discussing new ways i'm integrating it.